
Agentic Engineering — The AX Stack
How To Get 90% Accuracy on One-Shot Feature Work with AI Agents
My job at Wonderly has gotten weird over the past year. I spend most of my day voice-typing into 5 terminal windows running Claude Code for about 10 hours a day. 9 instances is too many. Two is too few. 5-7 feels right.
My output is maybe what 10 people used to produce. I'm doing it in a backend language I have zero experience in. With 90% accuracy.
When I hear people say AI experiments aren't working, I'm genuinely flabbergasted. I'd love to be a fly on the wall where people say AI is failing them and just see how they're using it. Because generally speaking, if you're not getting insane results from these tools, you're not doing something right.
That's how you should view things now. If the AI is getting it wrong, it's because you didn't tell it how to do it well enough. It didn't have the correct guardrails, enough information, enough context. And not only is it your fault, but you must correct it — and if you get a whole eng org doing that across every PR, 24/7, you bet your ass that compounds.
I don't care to debate whether software engineering is "solved." Probably not. But you don't have to trust me on any of this. I'm not pitching a hypothesis — I've been doing this every day for months. Stripe is doing it. Intercom is doing it. The research is linked below. Go read it. Go verify it yourself. And if you want to skip all that and just try it, the entire system is open source and you can deploy it in an afternoon.
By the end of this, I hope you can take this post, and get to where we are in 30 days.
The Compound Loop
Here's why most AI coding setups plateau: every conversation starts from basically zero.
You open your tool. It suggests something. Maybe it's good, maybe it's generic. Next time you open it, it has zero memory of what happened. Zero knowledge of your codebase conventions — other than some basic code indexing or half assed "rules". Zero awareness of the gotcha another team hit last week with the Redis cache TTLs, the new shared services that are available, the components you already built.
Now — some people are already doing something about this. You've got .cursorrules, CLAUDE.md, .agents folders. And if you look closely at the people getting really good results with AI coding, I guarantee they have some special shit in those files. Carefully crafted instructions. Codebase-specific patterns. Hard-won gotchas.
The problem is it's fragmented.
One engineer has amazing Cursor rules. The person next to them is using Claude Code, which doesn't read the .cursor/ folder at all — it reads CLAUDE.md. Someone on the backend team is using Codex, which reads AGENTS.md. None of these tools read each other's config files. So that amazing set of rules one person wrote? It only works for people using the same tool. And nobody's learning from each other. Nobody's compounding across the team.
Then it gets worse. You have multiple repos. The frontend patterns conflict with the backend patterns. Someone tries to standardize by dumping a 500-line instruction file into every repo. Now your engineers are pissed because you're injecting a ton of irrelevant context into their sessions and they feel less productive than before you tried to help.
This is why you need a centralized, curated, company-owned knowledge base. Not to replace the individual engineer's workflow — they can use whatever tool they want. But the knowledge that makes agents good at your codebase has to be shared. The gotchas, the patterns, the conventions. If that knowledge lives in one person's .cursorrules file, it dies when they go on vacation.
That's the compound loop. We maintain curated docs that describe how our team builds software — not generic "use React hooks" advice, but specific "here's how WE do data fetching in THIS codebase." The agent reads these before writing a single line of code. Every time a PR merges, we extract learnings. What did the reviewer catch? What patterns emerged? Those learnings feed back into the KB. Not into one person's config file. Into the shared knowledge base that every agent, every tool, every engineer has access to and it updates globally for everyone.
Day 1 accuracy: 40%. Day 30: 90%. Not because the model got smarter. Because the context got better.
Two feedback speeds:
Fast (every session): A hook analyzes what happened. Missing skill? Wrong KB info? Gaps post to Slack with a pre-filled GitHub issue. The team triages and fixes.
Deep (every PR): After merge, a compound skill extracts learnings — corrections, review feedback, structural changes — and routes them. Team-wide knowledge goes to the KB. Project-specific stuff stays local.
The KB gets better every day. Not through a grand documentation initiative. Through the natural byproduct of doing work.
The Evidence
Vercel tested this directly. Curated 8KB docs index: 100% pass rate. On-demand RAG retrieval: 53%. RAG performed identically to having no docs at all. The curated, always-available knowledge base was the only thing that moved the needle. That's why we use full-text keyword search — no embeddings, no vector DB. Embarrassingly simple and it works better than everything else.
Stripe merges 1,300+ agent-produced PRs per week. Zero human-written code. Agent writes, linter formats, type checker validates, CI runs tests. They call it "Blueprints." I call it the obvious right architecture.
Intercom runs 100+ skills. The top 5 users of their production console aren't engineers — they're design managers, support engineers, PMs. Non-engineers are the power users. (This is why I think feature dev is dead.)
TELUS saved 500,000 engineering hours. Zapier hit 89% AI adoption org-wide. 57% of organizations already have agents in production.
Jason Lemkin put it well: the value isn't in building AI — it's in deploying it into your specific workflows, training it properly, and measuring the output. He says at even the best startups, maybe 30% of the management team has actually deployed an AI tool with real ROI in the last 30 days. In general interviews, it's single digits. That gap is either your opportunity or your risk, depending on which side you're on.
The pattern: curated context beats generic prompts. Deterministic tooling handles validation. Humans stay in the loop for review. Nobody ships agent code without a human approving it.
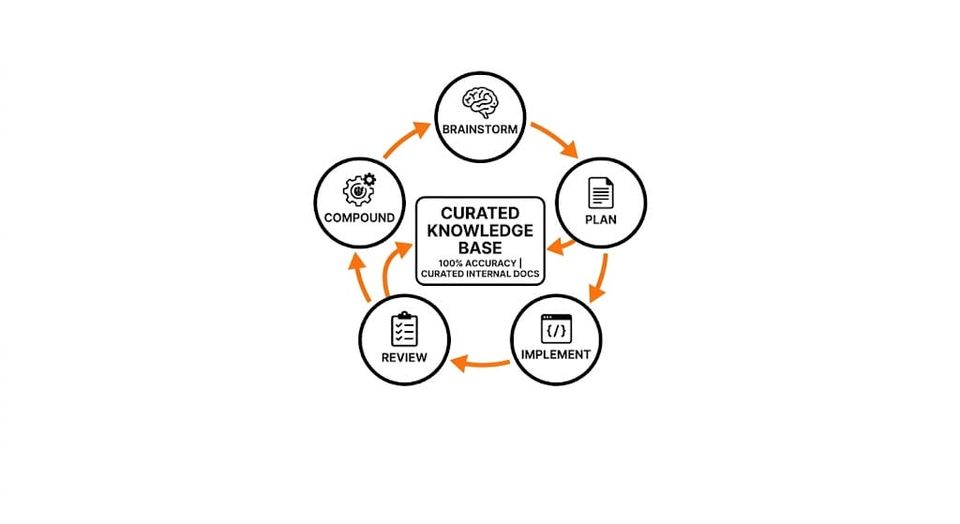
The Process
It's a cycle. Each step has a specific output:
Brainstorm → design doc. When you don't know what you don't know. You may start here (or my preference - just start with plan).
Plan → implementation plan with verification strategy. The agent researches the codebase using parallel sub-agents, loads KB docs, and designs step-by-step how to build it AND how to prove it works. Encourage exploration to make use of existing code (otherwise AI will always prefer to write new code).
Implement → code. Step by step, build-checked after each step. One CI retry on failure. Same error twice? Stops and asks a human. Bounded iteration. Local CI is extremely important here.
Review → bugs list. several sub-agents in parallel, each reviewing from a different lens: security, API design, performance, code reuse, patterns, clean code, simplicity, AI slop detection.
Compound → learnings back to KB. The flywheel turns.
Voice-to-text tip: use Wispr Flow or Claude Code's native voice. You naturally give 3-4x more context when speaking vs typing. Nobody types three paragraphs of background. People say it naturally. That extra context is exactly what the agent needs. $10/month cheat code.
What I've Learned
The KB is the hard part. Not the model. Not the IDE. Not the framework. The quality of your documentation determines your output quality. If the KB is empty, you're back to generic pre-training. First two weeks of rollout are your best engineers writing docs and watching PRs for similar mistakes. Skip this and nothing else works. Its mostly a people problem but a problem nonetheless.
Non-engineers adopt faster. Engineers have muscle memory — they want to write it themselves. PMs and designers just want the thing built. Give them a Codespace with the agent pre-configured and they ship their own bug fixes and minor improvements. Setting up codespace may take a while - but is worth the effort. Bonus: add a slack bot to spin up the codespace easier - spend time pre-loading the codespace with claude code or codex etc. Users can log in quickly and get to work with a 100% isolated environment.
The compound loop is the moat. Company A runs it. Company B just uses autocomplete. After 6 months, Company A's agents one-shot everything because they've accumulated hundreds of codebase-specific learnings. Company B is at day-one accuracy. The gap widens every week.
Review is the correct bottleneck. Everything else gets automated. The one thing that stays human is the final review — judgment, context, taste. If you're bottlenecked on review, the answer is more reviewers, not less review. Consider stacked PRs.
Simple search beats RAG. Full-text keyword search on curated docs works better than vector embeddings. The agent doesn't need cosine similarity to find "React testing patterns." On 50-200 curated docs, this is always sufficient.
Where It Breaks → The Right Bottleneck
If you do this well, you become a review-constrained organization. That's not a bug — that's the goal.
Everything else gets automated: writing code, running tests, creating PRs, fixing lint, addressing review feedback. The one thing that stays human is the final review. Judgment. Context. Taste. "This technically works but it's the wrong approach."
If you're doing continuous deployment — merge to main, push to prod, multiple times a day — then review is the correct bottleneck. You want fast, high-quality review, not less of it. Invest in:
- Stacked PRs — 500 lines reviews faster than 1,500
- Review bots (Propel, etc.) — catch the mechanical stuff so humans focus on judgment
- The compound loop — every review correction feeds back so the same issue doesn't come up twice
- More reviewers, not less review — if you're bottlenecked, the answer is more humans reviewing or more testing in CI that you can trust, not fewer checks
The cold start is real — your KB needs seeding. Greenfield is harder than incremental. Security needs to be structural. But those are setup costs, not ongoing constraints. The ongoing constraint is review, and that's exactly where you want humans to be.
Set This Up
I open-sourced an entire system pieced together from public data sources and my own experience at my day job: Knowledge Base server (~700 lines of Python), 19 skills, 5 enforcement hooks, 18 guides, GitHub Actions for automated compound loops, and templates for every major coding agent.
It's opinionated. Stacked PRs. Retrieval-led reasoning. Mandatory code review. Keyword search over RAG. Bounded iteration. Security as a default review perspective.
The process:
- Deploy the KB server
- Point it at your docs repos (or have it auto-generate seed docs from your codebase with
/seed) - Install the skills for your coding agent
- Run the brainstorm → plan → implement → review → compound cycle
- Watch the one-shot rate climb from 60% to 90% over 30 days
Every pattern in the repo is sourced from public domain research — Anthropic, Vercel, Stripe, and others. Full sources documented.
If you're doing something similar, I want to hear about it! Open a PR with your case study. or @ me on linkedin / X. The honest failures are more valuable than the success stories.
Most of the ideas in here aren't original — they're compiled from the sources linked above and battle-tested at Wonderly.