
Vibe Robot: teaching a robotic arm a pick and place task
I periodically go on side quests. And they mostly involve some kind of hardware. I've been dabbling in robotics for years thanks to a friend's robotic arm i've been borrowing.
First I tried to build a robotic massager. Basically I strapped a theragun to a pressure sensor and then strapped that to the arm. I got it to eventually give my wife a pretty dangerous and terrible massage. It only put one hole in my drywall when it went haywire. Unfortunately i dont have that on camera.
So after maybe 5-6 failures over the past 2-3 years, this is the first time I got an end-to-end policy to actually work, just from imitation learning on demos. And thank god I didn't have to try to get Nvidia's omniverse working again...
What changed
ACT — Action Chunking Transformer. The big change for me is how you teach a robot to do things now. On my old GPU under my desk (a 3080) I can train an ACT model that basically acts like an LLM but instead of predicting the next letter (token), it predicts the next few action states. You feed it a camera frame and the position of the arm and give it a bunch of demos. Shockingly this worked and it only took a weekend. I’ve spent weeks just trying to get reinforcement learning working in a simulated environment, only to load it onto the arm in the real world and have it flail around like a wet noodle....
Now is basically the LLM moment for robotics. The AI architecture that makes language models work is now making robot policies work too. This is not a very original observation, but it didn’t feel real to me until i actually trained one myself.
What I built
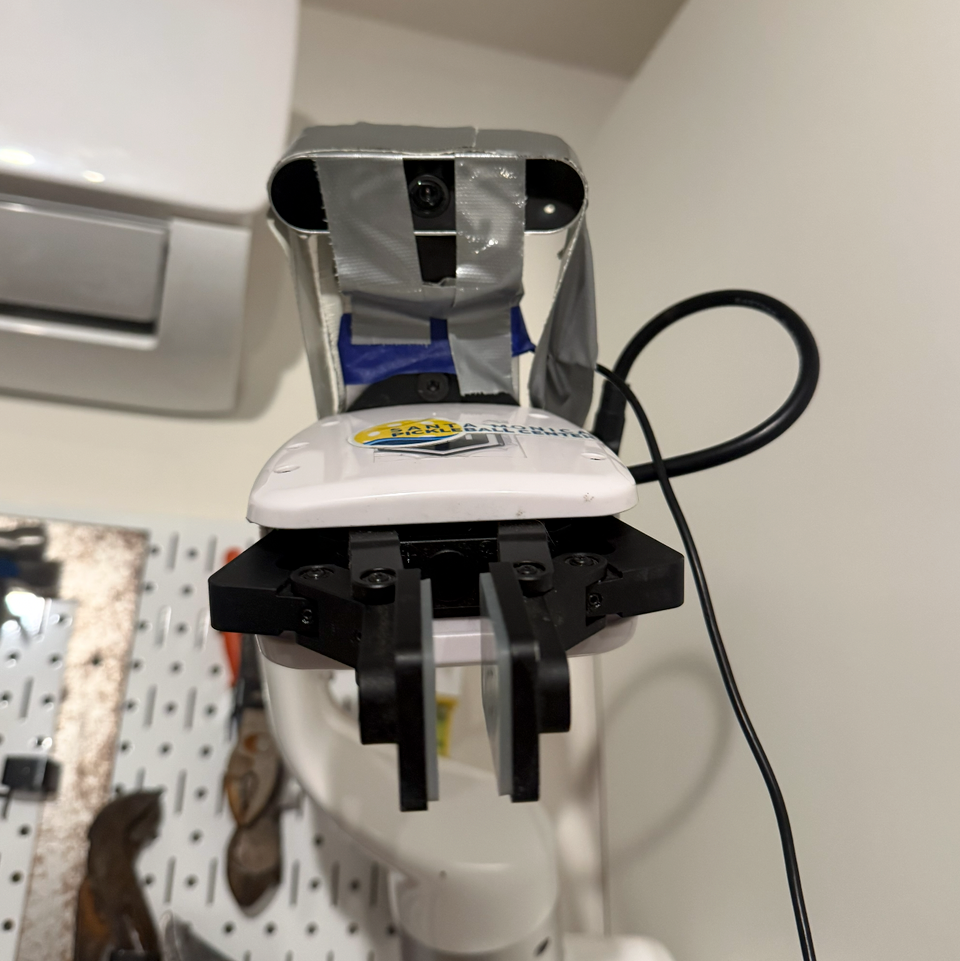
For training, I took an xArm 6 and duct-taped a 640×480 USB webcam to it (literally). For demos, i physically pushed the arm through each motion while clicking the gripper open/closed in xArm Studio. I recorded 122 demos. In the academic papers - they cited only 50 are needed but they had an additional overhead camera - I did not.
The task was to grab a small syringe and place it in a box - this is part of the microplastics kit ... and wouldn't it be cool if the robot could pack orders for me!
I trained the ACT model for 10,000 steps on the 3080. Each training took only about about 25 minutes. The trained model runs on my Mac and predicts 100-step action chunks. Basically it then executes 30 of them before re-observing (guessing the next 100).
What went wrong
It didn’t work on the first try. Or the tenth.
I ran a bake-off across 10 checkpoints (10 fully trained models, yes 25-30 minutes for each one) and I wrote down what broke. The failures we're pretty much the same each time: the arm (very roughly) knew where to go, but it had no idea when to grab the syringe and when to drop it.
There were four bugs separated “almost works” from “omg it works”:
First: my Z safety floor was 8mm above where the arm actually needed to be to grab anything. Basically left unattended it would scratch the shit out of my workbench table top. I’d clamped the lowest allowed Z at 180mm. Then I audited the data and found half my demos had the gripper closing below 180. The policy kept commanding “descend more” forever, physically blocked from the state it was trained to expect. Dropped the floor to 168mm.
Second: LeRobot’s default image transforms include random rotation and translation augmentation. For pick and place this is poison — you’re telling the model the action is the same regardless of where the object is in the frame. Disabled the spatial transforms, kept color jitter only.
Third: I was executing only 10 action steps before re-planning. ACT predicts 100 actions per chunk. At 10 steps, the arm barely moved before getting a fresh chunk that predicted the same descent. Bumped to 30. Actual descent speed tripled.
Fourth, and this one took the longest to figure out: the gripper close is structurally rare in the data. In my demos the gripper snaps shut in 1-2 frames. Out of 82,000 training frames, maybe 150 are “transition” frames. The model never reliably learned to trigger it because it almost never saw it. I COULD have d
What’s learned vs hardcoded
I did cheat a little bit.
I hardcoded at deploy time the Z floor clamp, an orientation lock so the gripper stays level, n_action_steps, and an auto-close override.
The override is the part to caveat hardest. The policy never reliably triggers the close on its own. So the deploy script watches for “arm sitting below Z=170mm for 1.5 seconds with gripper still open” and forces it closed — and keeps forcing it until the gripper is physically shut and the arm has started lifting. Then control goes back to the policy.
So when i say “the policy does 95%” — the spatial trajectory is policy-driven. The gripper close moment is a 30-line rule. The principled fix is more training data where the close transition is stretched over many frames instead of one. I shipped the cheap fix.
Why this points somewhere big
Watching the arm finally work, the thing that hit me: you don’t need a $30K teleop rig.
The whole field has been built around expensive data collection setups. ALOHA’s leader-follower bimanual, UMI’s GoPro-on-a-grabber. Brilliant engineering. Also a barrier to anyone who isn’t a well-funded lab.
I trained this by pushing the arm around by hand with a USB webcam zip-tied to the wrist. The model doesn’t care that my demos are slower than ALOHA’s — it cares that they’re consistent.
So the bottleneck stops being the rig. It’s a phone strapped to a robot wrist and a Python script that timestamps frames and arm states. Record someone doing the dishes. Sorting parts. Opening a drawer. Train a policy per task.
This isn’t a 2030 prediction. It’s what the pipeline i just built does, generalized one step.
What’s next
Stretch the gripper close transition over half a second in the next round of demos and see if that fixes the rare-event problem from the data side. Swap the hand-push teleop for a phone-mounted setup. Stack a second task on the same robot.
What I took from this
Read the experimental setup of every paper, not just the number at the bottom. “50 demos is enough” assumes a 4-camera bimanual rig. A single wrist cam is different (and took roughly double the amount of examples).
Position prediction converges way faster than action-trigger timing. Across 10 checkpoints the policy reliably learned where to go. When to grip was the long pole every time. This might have just been because the transition states for the closed gripper were underrepresented in the data... but this is a gotcha to keep in mind in the future. If there's an important step that happens too fast, it may not make its way into the model. Anything that happens in 1-2 frames of a thousands-frame demo is structurally underrepresented and no hyperparameter sweep fixes it.
Augmentation isn’t free. Spatial transforms broke spatial reasoning. Color jitter only for pick and place.
Hybrid ML + deterministic engineering isn’t a failure. It’s just recognizing which problems are statistical and which are deterministic, and using each tool appropriately.